Yesterday, I tried out Stability AI’s four Control-LoRAs but mentioned that I did not understand the output of the Revision “image-mixing” workflow. I’ve since done a bit more experimentation...
Get caught up:
Part 1: Stable Diffusion SDXL 1.0 with ComfyUI
Part 2: SDXL with Offset Example LoRA in ComfyUI for Windows
Part 3: CLIPSeg with SDXL in ComfyUI
Part 4: Two Text Prompts (Text Encoders) in SDXL 1.0
Part 5: Scale and Composite Latents with SDXL
Part 6: SDXL 1.0 with SDXL-ControlNet: Canny
Part 7: Fooocus KSampler Custom Node for ComfyUI SDXL
Part 8: SDXL 1.0 with SDXL-ControlNet: OpenPose (v2)
Part 9: Stability AI Control LoRAs
Part 10: This post! Wow, ten already?!
About Revision
Quoting from source: “Revision is a novel approach of using images to prompt SDXL. It uses pooled CLIP embeddings to produce images conceptually similar to the input. It can be used either in addition, or to replace text prompt.”
A day later... I think maybe I have a handle on this: Using the CLIP AI model to “interpret” two images and generate an mash-up of the concepts prevalent in each. The keyword is concepts, and the output may not contain the literal form of the images.
No-Code Workflow
First, download clip_vision_g.safetensors from the control-lora/revision folder and place it in the ComfyUI models\clip_vision folder.
Based on the revision-image_mixing_example.json, the general workflow idea is as follows (I digress: yesterday this workflow was named revision-basic_example.json which has since been edited to use only one image):
- First, load an image.
- Then, pass it through a CLIPVisionEncode node to generate a
conditioningembedding (i.e. what the AI “vision” “understands” as the image). - Next, create a prompt with CLIPTextEncode and then ConditioningZeroOut.
- Finally, use the unCLIPConditioning node to apply this prompt guidance to the conditioning (i.e. provide more guidance to strengthen or weaken what AI “understands” as the image) - note that by default, the prompt will be zeroed out!
- Repeat for the second image so that we can “mix” them together - wire up the output from first unCLIPConditioning as the
conditioninginput to the second unCLIPConditioning node. - At this point, create a negative prompt in a similar way, CLIPTextEncode wired up to ConditioningZeroOut.
- The rest of the workflow is a basic KSampler node followed by VAEDecode.
As mentioned, since the positive and negative prompts both are wired up to ConditioningZeroOut nodes, both prompts will therefore be ignored. To test say a negative prompt, simply right-click the following ConditioningZeroOut node and Bypass it - there is no need to edit the workflow beyond this.
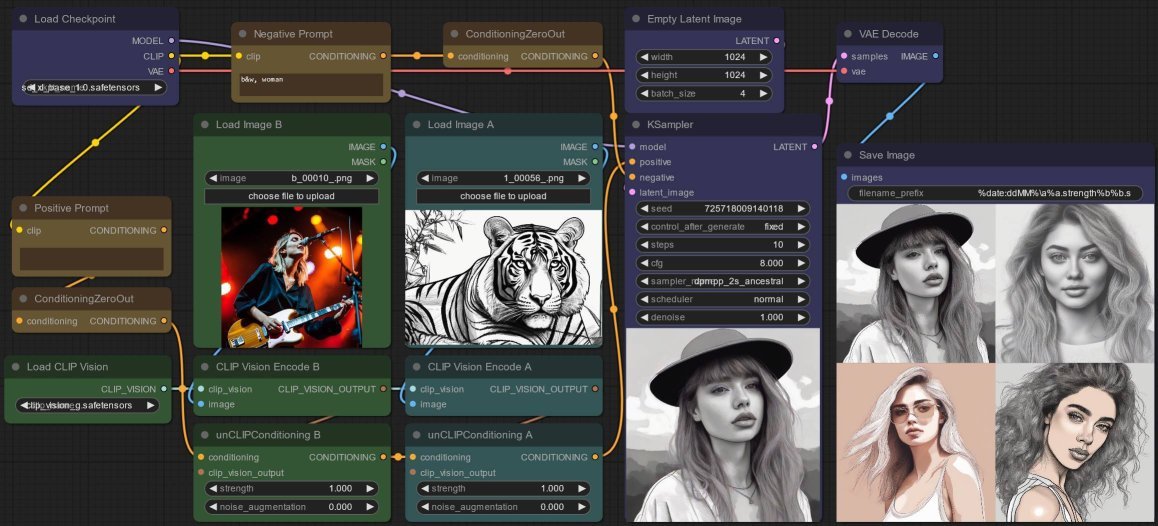
Experiment 1: Identical Strengths
In these tests, I use two images I generated via SDXL - the first is a female lead singer and guitarist, the second is a tiger line art (which I generated to test the Sketch Control-LoRA previosuly).
Also, I keep the Sampler the same with a fixed seed. Only belatedly do I realize I should not use an ancestral sampler, so that the output always converges, but surprisingly, re-running gives me the same generated images (at least to my failing, human eyes).
I start with both unCLIPConditioning strength at 1.0 - as you can see, I get female portraits in a line art style, with hints of pale red and yellow (which so happens to be skin color), but totally devoid of tigers... hmmm...
Experiment 2: Weakened Strength
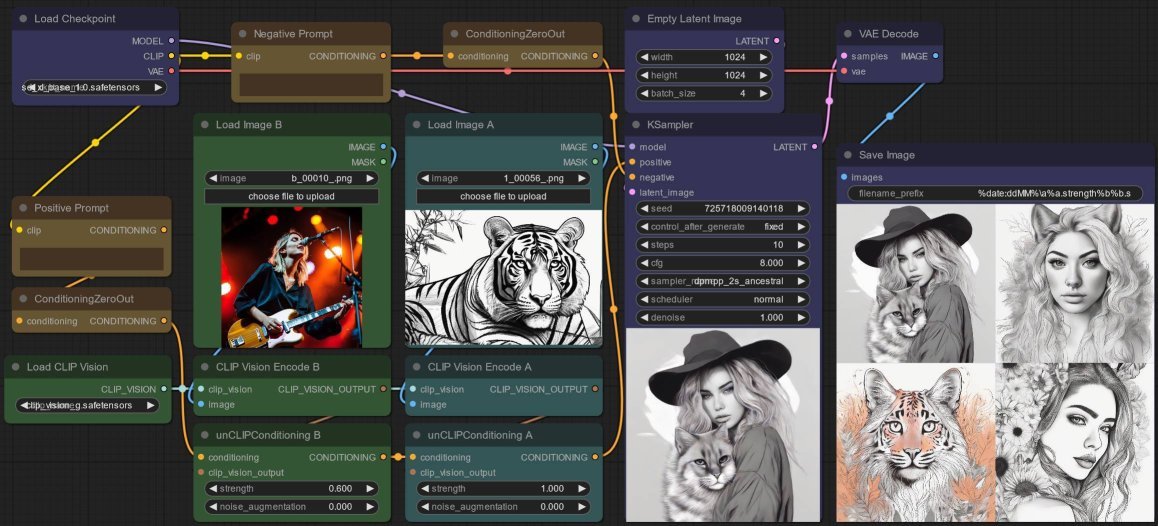
I weaken the strength for the image of a lady guitarist to 0.6 - and I get a perfect mix of black and white, mostly line art-y outputs containing both subjects! Nice!
- the first image is a woman holding a “tiger” (well... “cat”) -still retaining her hat, as compared to that in the first set,
- the second is a woman with tiger ears - still retaining the her mane just like in the first set,
- the third is a tiger,
- the fourth is a woman - still retaining the angle of her head from the first set.
Lowering further to 0.4 gives me all tigers (well... tigers and cats), so clearly that is too low.
Experiment 3: Negative Prompt
Up to now, the images I get are predominantly black and white, so I test b&w as a negative prompt - and what do you know, it works! Remember to Bypass the ConditioningZeroOut node!
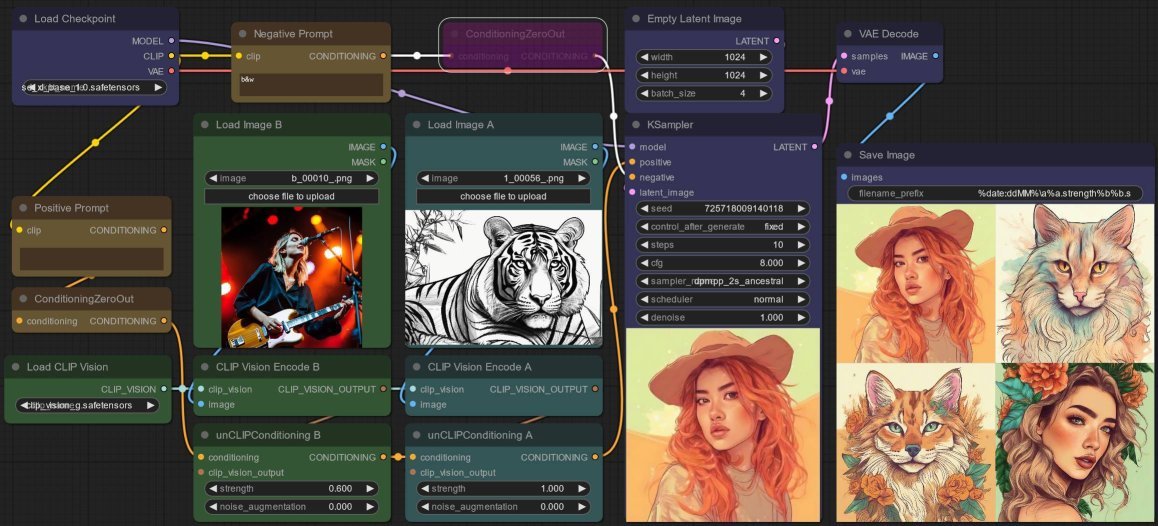
I get colored images mostly in pale reddish-yellowish hues which is a “concept” present in the first image. In fact, if you flick back and forth between the image below and the prior two outputs, it is quite obvious that this set and the prior ones continue to have other “concepts” in common like some sort of narrative thread:
- in the first image, its the hat,
- in the second image its the mane and ears,
- and in the fourth its clearly the same angle.
So the negative prompt is certainly sufficient to alter (i.e. condition) the output in a meaningful but subtle way.
Alas, the images are either a woman or a tiger, not like previously where the first and second images are clearly mash-ups. So let me try reinforcing the negative prompt...
Experiment 4: Stronger Negative Prompt
Expanding the negative prompt to b&w, woman gives me more “tigers” (well... “cats”) so this also works as expected. I do like the last image still features a woman (well... “girl”) holding a small “tiger” (well... “cat”, am I repeating myself?). This confirms that the “image-mixing” mash-up is still working and the “concepts” I mention continue to influence the output...
And finally, I get it! Revision has given me the cutest and most interesting image to date - the fourth one: a brand new image that somehow contains elements or “concepts” found in the two original images.
This is an image I never would’ve been able to prompt! There are “concepts” from the first image: a woman, reddish-yellowish hue (weakened though it may be), and “concepts” from the second image: a tiger, foliage, line art style. Additionally, it is clearly influenced (i.e. conditioned) by the negative prompt so as not to fixate on generating predominately black and white images of women, like in the first experiment.
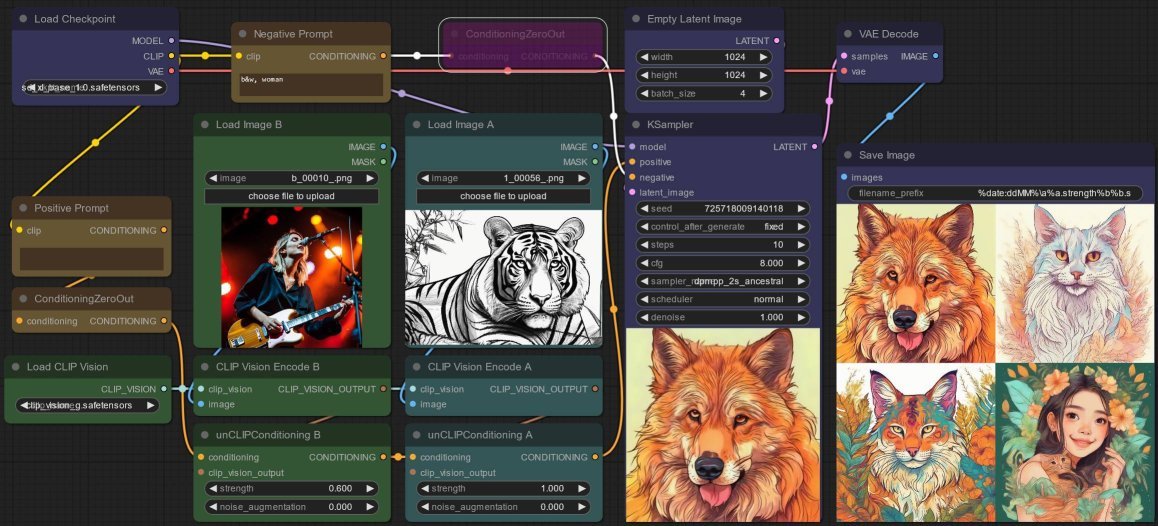
Experiment 5: No Positive Prompt?
Finally, what about a positive prompt you say?
Well I tried a few but any positive prompt seems to totally dominate the output, e.g. tiger gives me all tigers, oil painting literally generated a picture of a man holding a paintbrush and palette. No doubt there are other situations where positive prompt would reinforce some desired concept but without a way to control the strength, I do not know how to use it effectively.
Therefore, to conclude, I would not suggest using a positive prompt - instead, focus on adjusting the negative prompt only. Have fun!