Onward with SDXL and ComfyUI! Sometimes I want to tweak generated images by replacing selected parts that don’t look good while retaining the rest of the image that does look good. Rather than manually creating a mask, I’d like to leverage CLIPSeg to generate a masks from a text prompt.
Get caught up:
Part 1: Stable Diffusion SDXL 1.0 with ComfyUI
Part 2: SDXL with Offset Example LoRA in ComfyUI for Windows
Part 3: This post!
About CLIPSeg
CLIPSeg takes a text prompt and an input image, runs them through respective CLIP transformers and then auto-magically generate a mask that “highlights” the matching object.
About ComfyUI-CLIPSeg
Back in September last year, I coded CLIPSeg into my Stable Diffusion workflow, see see Adding CLIPSeg automatic masking to Stable Diffusion.
Of course this time, my aim is to just use what smarter people have already developed. A quick search led me to a custom ComfyUI node, ComfyUI-CLIPSeg by biegert! It is similar to what I did, in that it also uses cv2 to implement some sort of dilation algorithm, but also does a Gaussian blur too. Excellent!
Install ComfyUI-CLIPSeg
On Windows, download the repository as a ZIP and expand. I installed it slightly differently, since I placed all files in ComfyUI\custom_nodes\CLIPSeg\ and then copied ComfyUI\custom_nodes\CLIPSeg\custom_nodes\clipseg.py to `ComfyUI\custom_nodes\CLIPSeg\__init__.py.
Assuming ComfyUI is already working, then all you need are two more dependencies. If you used the portable standalone build of ComfyUI like I did then open your ComfyUI folder and:
.\python_embeded\python.exe -s -m pip install matplotlib opencv-pythonOn mac, copy the files as above, then:
source v/bin/activate
pip3 install matplotlib opencv-pythonCreate No-Code Workflow
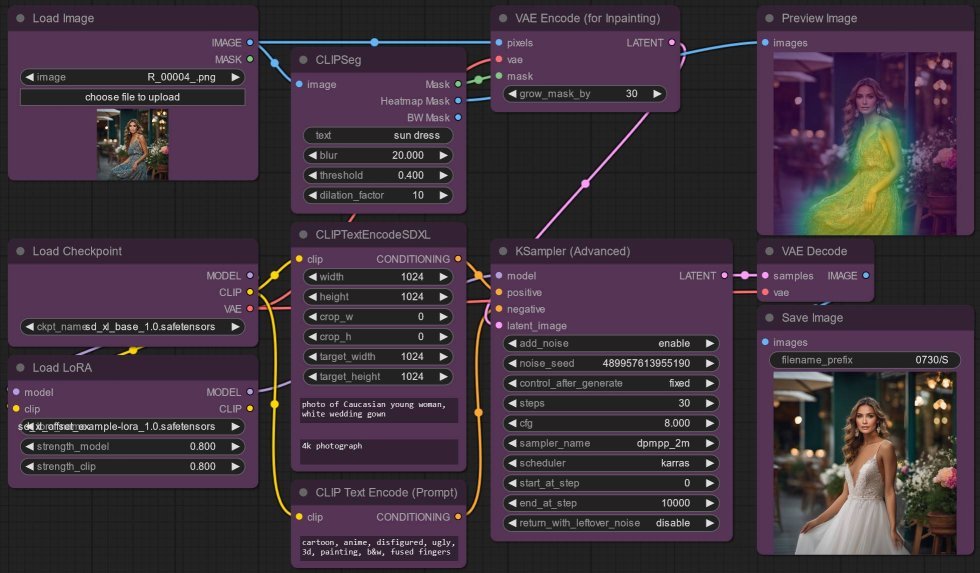
In short, for the txt2mask:
- LoadImage, image output to...
- CLIPSeg, mask output to...
- VAEEncodeForInpaint
- also add PreviewImage and connect the input to either the CLIPSeg heatmap mask or BW mask output for visualization
And then for the inpainting with SDXL:
- as before, CheckpointLoaderSimple to load SDXL
base, with vae output to VAEEncodeForInpaint, and model and clip output to... - LoraLoader to load
offset-example-lora(this is optional) - CLIPTextEncodeSDXL with positive prompt
- CLIPTextEncode with negative prompt and input clip from CheckpointLoaderSimple
- KSamplerAdvanced with
add_noiseenabled, andreturn_with_leftover_noisedisabled, then wire-up:- input clip from CheckpointLoaderSimple,
- input model from LoraLoader model output,
- input positive from CLIPTextEncodeSDXL output,
- input negative from CLIPTextEncode output,
- input latent_image from VAEEncodeForInpaint.
- VAEDecode and wire up:
- input vae from CheckpointLoaderSimple,
- input samples from KSamplerAdvanced latent output,
- and output image to...
- SaveImage
Go!
Don’t like the “sun dress”? Just set that as the CLIPSeg prompt!

Or want to do a “face” swap? Sure!

Of course manual masking is likely to achieve more precise results but I am just too lazy!