Stability.ai has released Stable Diffusion XL (SDXL) 1.0 (26 July 2023)! Time to test it out using a no-code GUI called ComfyUI!
About SDXL 1.0
Per the announcement, SDXL 1.0 is “built on an innovative new architecture composed of a 3.5B parameter base model and a 6.6B parameter refiner... The base model generates (noisy) latent, which are then further processed with a refinement model specialized for the final denoising steps”:
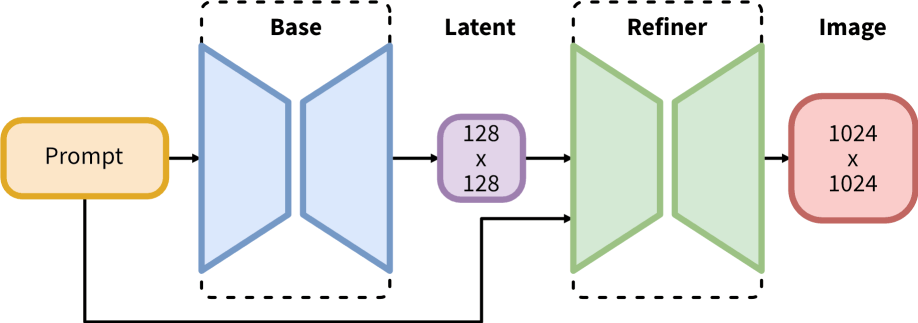 Source: HuggingFace.co SD-XL 1.0-base Model Card
Source: HuggingFace.co SD-XL 1.0-base Model Card
About ComfyUI
ComfyUI has a neat node-based UI, allowing nodes to be connected (wired) together into a workflow (pipeline). And best of all, it already supports SDXL 1.0 and runs on macOS without any special requirements aside from python3 and typical Python libraries (brew is not required).
ComfyUI is much easier than what I attempted previously in my 8 part series, where I started with the standard Stable Diffusion Python script for 1. txt2img, then gradually added features like 2. img2img, 3. txtimg2img, 4. mask+txtimg2img and 5. txt2mask+txtimg2img. Then I re-wrote my code from scratch and supported Safetensors, along the way testing CoreML.
Install ComfyUI
I am using Python 3.9.6 that came pre-installed with macOS 13.4.1. Oddly, ComfyUI does not seem to have a version number, but I downloaded mine a few days ago.
# Install ComfyUI in a working folder
git clone https://github.com/comfyanonymous/ComfyUI
cd ComfyUI
# Create virtual env and install dependencies
python3 -m venv v
source v/bin/activate
pip3 install torch torchvision torchaudio
pip3 install -r requirements.txt
# Make sure PyTorch supports Metal Performance Shaders (MPS)
python3 <<EOF
import torch
if torch.backends.mps.is_available():
print(torch.ones(1, device=torch.device("mps")))
else:
print("MPS device not found.")
EOF
# Output expected: `tensor([1.], device='mps:0')Download SDXL Models
SDXL models can be downloaded from HuggingFace. Create and account and login if required.
From stabilityai/stable-diffusion-xl-base-1.0:
- Navigate to Files and Versions,
- Download
sd_xl_base_1.0.safetensors, - And place it in the ComfyUI directory
./models/checkpoints.
From stabilityai/stable-diffusion-xl-refiner-1.0:
- Navigate to Files and Versions,
- Download
sd_xl_refiner_1.0.safetensors, - And place it in the ComfyUI directory
./models/checkpoints.
Create No-Code Workflow
Since we know the SDXL pipeline involves both the Base and Refiner model, we will re-create this workflow in SDXL, with no Python coding required.
Start ComfyUI and run the GUI in your browser of choice. For me, Safari uses less memory and has less UI bugs than Firefox.
python3 main.py
open http://127.0.0.1:8188/ In the browser UI, hit Clear to start fresh, and double-click the canvas to search for and add nodes.
The nodes I use are:
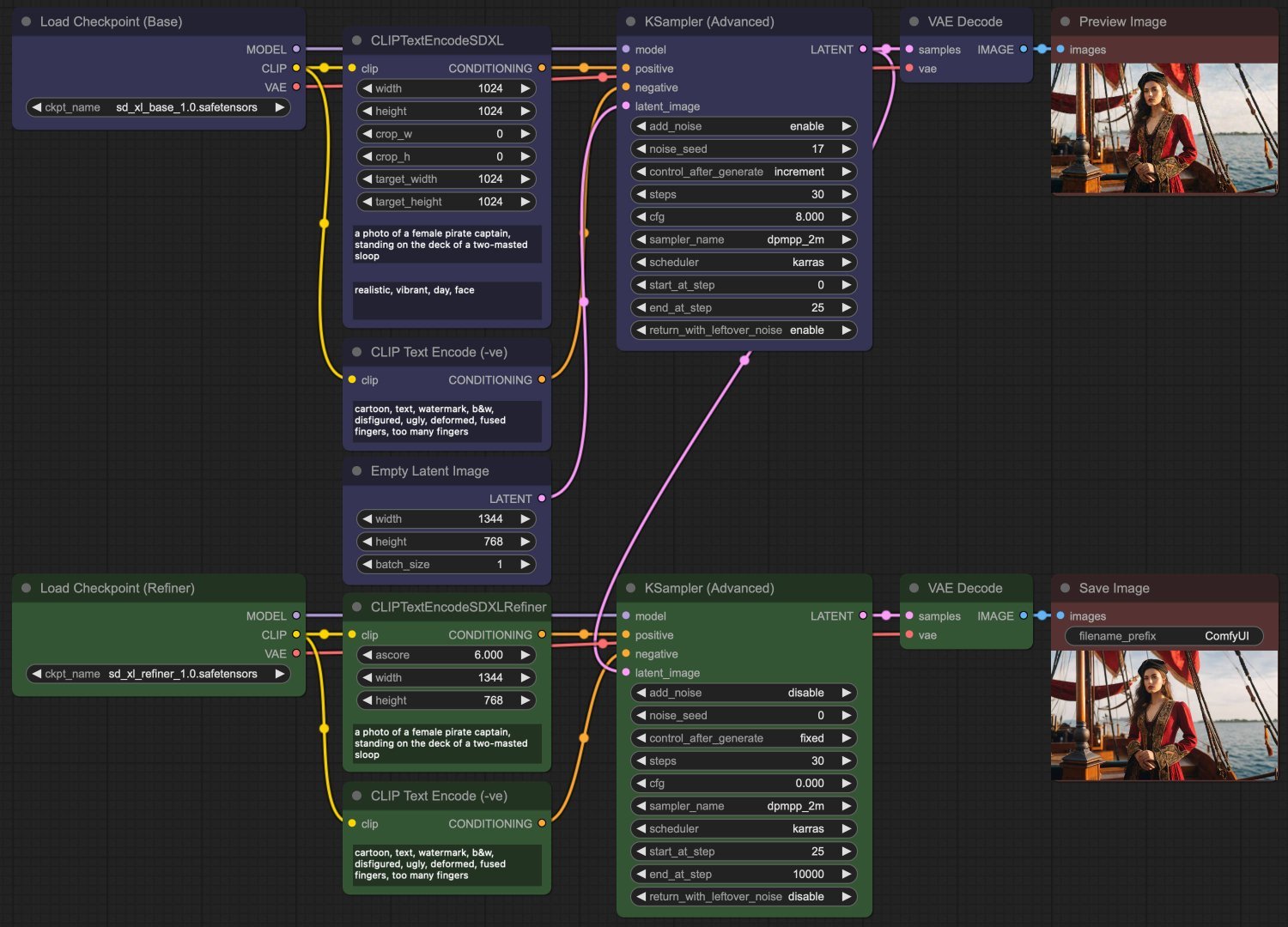
For the base model (in blue):
- Add a CheckpointLoaderSimple node to load
sd_xl_base_1.0.safetensorsand wire up outputs:- model --> model KSamplerAdvanced configured for
30steps, ending at step25, withadd_noiseandreturn_with_leftover_noiseboth enabled, - clip --> clip ClipTextEncodeSDXL,
- vae --> vae VAEDecode.
- model --> model KSamplerAdvanced configured for
- Configure ClipTextEncodeSDXL with a positive prompt in the first
CLIP_Gtext box and any “style” descriptions in theCLIP_L(aka “projection”) text box, and wire up the output:- conditioning --> positive KSamplerAdvanced.
- Add a CLIPTextEncode node with a negative prompt, and wire up:
- input clip from CheckpointLoaderSimple above, and
- output conditioning --> negative KSamplerAdvanced.
- Add a EmptyLatentImage node for size
1344 x 768and optionally, increase the batch_size to generate multiple outputs per run (to avoid re-loading the models), and wire up the output:- latent --> latent_image KSamplerAdvanced.
- Next, wire up
- KSamplerAdvanced latent --> samples VAEDecode,
- and VAEDecode image --> image PreviewImage.
The refiner is piratically the same (in green), except the output from the base model is wired as input to the sampler:
- Add a CheckpointLoaderSimple node to load
sd_xl_refiner_1.0.safetensorsand wire up outputs:- model --> model on a new KSamplerAdvanced configured for
30steps, starting at step25, withadd_noiseandreturn_with_leftover_noiseboth disabled, - clip --> clip ClipTextEncodeSDXLRefiner,
- vae --> vae on a new VAEDecode.
- model --> model on a new KSamplerAdvanced configured for
- Configure ClipTextEncodeSDXLRefiner with a positive prompt (feel free to use the same or a different one) and Aesthetics Score (ascore), and wire up the output:
- conditioning --> positive KSamplerAdvanced
- Add a CLIPTextEncode node with a negative prompt, and wire up:
- input clip from CheckpointLoaderSimple above, and
- output conditioning --> negative KSamplerAdvanced - don’t try to wire up the first CLIP-encoded negative prompt, that never works.
- Wire up:
- the first base-model-derived KSamplerAdvanced latent --> latent_image on this second KSamplerAdvanced,
- latent --> samples VAEDecode.
- and finally wire up VAEDecode image --> image SaveImage.
Experiment with the parameters! The ComfyUI SDXL Example images has detailed comments explaining most parameters.
Go!
Hit Queue Prompt to execute the flow!
The final image is saved in the ./output while the base model intermediate (noisy) output is in the ./temp folder and will be deleted when ComfyUI ends. You can also Save the .json workflow, but even if you don’t, ComfyUI will embed the workflow into the output image. To load the workflow at a later time, simply drag-and-drop the image onto the ComfyUI canvas!
Here is the output from one sample run:

Watch out for Memory Pressure! Open Activity Monitor.app and in the Memory page, keep an eye on Swap Used. On my base model M2 Mac mini (10 GPU), a typical run takes uses a total of over 40 GB physical + swap memory.
- Close every other running app
- Periodically hit Ctrl+C to terminate Python and free memory. Upon re-starting ComfyUI, the browser UI will re-connect without loosing the current workflow (as long as you do not close or refresh it).
Regarding memory, as a side note for Windows users: I tried the same workflow on my Nvidia GeForce GTX 2060 with 12GB of RAM, and I could not run it successfully due to insufficient GPU memory! I had to split the Base and Refiner models into two workflows and save/load the intermediate latent.
Experiment with Image Sizes
The first Stable Diffusion release was trained on 512 x 512 images. However, SDXL is trained on 1024 x 1024 images and supports additional aspect ratios per Stability.ai documentaton, which can be used in portrait or landscape mode:
| Square | Portrait | Landscape | Aspect |
|---|---|---|---|
| 1024 x 1024 | 1:1 | ||
| 896 x 1152 | 1152 x 896 | Closest to 4:3 (SD) | |
| 832 x 1216 | 1216 x 832 | Closest to 3:2 (Photo) | |
| 768 x 1344 | 1344 x 768 | Closest to 16:9 (HD) | |
| 640 x 1536 | 1536 x 640 | 2.4:1 (Widescreen) |
Experiment with Samplers
For those interested, Stable Diffusion Art has a good explanation and comparison of Samplers in their ‘Comprehensive Guide.’ For “something fast, converging, new, and with decent quality” they suggest DPM++ 2M Karras with 20-30 steps, or UniPC with 20-30 steps (If you are not concerned with generating reproduce-able images, then FYI, some people prefer ancestral samplers for sheer artistic quality).
However, on my mac, the UniPC sampler gives an error: NotImplementedError: The operator 'aten::_linalg_solve_ex.result' is not currently implemented for the MPS device. To solve this, run ComfyUI enabling PyTorch CPU fallback with:
PYTORCH_ENABLE_MPS_FALLBACK=1 python3 main.pyIn non-scientific tests on my base M2 mac, UniPC took under 6 minutes, DPM++ 2M Karras just over 5 minutes, whereas the slowest samplers can take up to 20 minutes to complete. On Windows, with an Nvidia GTX 2060, each run (if I could use both models together) completes in a mere minute! Talk about overselling!