SDXL 1.0 uses two text prompts used to guide image generation. In my first post, SDXL 1.0 with ComfyUI, I referred to the second text prompt as a “style” but I wonder if I am correct. I have no idea! So let’s test out both prompts...
Get caught up:
Part 1: Stable Diffusion SDXL 1.0 with ComfyUI
Part 2: SDXL with Offset Example LoRA in ComfyUI for Windows
Part 3: CLIPSeg with SDXL in ComfyUI
Part 4: This post!
About CLIPs
Image generation with Stable Diffusion starts with the need to “understand” the input text as it relates to images. The neural network “encoder” to do this is OpenAI’s Contrastive Language-Image Pre-training (CLIP). SDXL uses OpenCLIP, an open-source implementation of CLIP, trained on an open dataset of captioned images.
In ComfyUI these input parameters are represented as:
CLIP_G= text_encoder (CLIPTextModel)CLIP_L= text_encoder_2 (CLIPTextModelWithProjection)
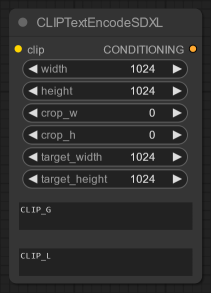
Checking the SDXL documentation, the two text inputs are described as:
text_encoder (CLIPTextModel) — Frozen text-encoder. Stable Diffusion XL uses the text portion of CLIP, specifically the clip-vit-large-patch14 variant.
text_encoder_2 ( CLIPTextModelWithProjection) — Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of CLIP, specifically the laion/CLIP-ViT-bigG-14-laion2B-39B-b160k variant.
That doesn’t clarify at all! I did check out SDXL Prompt Tests by Markus Pobitzer... but that just confused me further.
Time to experiment! In all cases I used the Base SDXL 1.0 model (no refiner) and identical parameters:
- image size =
1024x1024 - sampler =
dpmpp_2m, scheduler =karras - steps =
30, cfg =8.0 - seed = fixed
674690372 CLIP_Gpositive = “an angel with wings outstretched landing in the middle of a busy road”- negative prompt = “text, watermark, b&w” (except the B&W output in the last experiment set)
Experiments with “Official” Styles in CLIP_L
By official, I mean that these are the so-called “styles” in the free-to-use Clipdrop SDXL image generator:
I’ll just call them the “Official” styles:
- no style - which I assume means leaving
CLIP_Lblank (although actually usingno styleproduces strikingly similar results) animephotographicdigital artcomic bookfantasy artanalog filmneon punkisometriclow polyorigamiline artcinematic3d modelpixel art
As you can see below, using a single “official” style in the CLIP_L field faithfully produces the expected stylistic representation. Excellent!

This means my CLIP_G can be a textual description of the image (adjectives and nouns), and style can be applied (projected) independently.
More Experiments with Styles
I want to make sure styles belong in CLIP_L - what happens if I place styles in CLIP_G instead? What if I use only one prompt to embed styles, similar to Stable Diffusion 1.0/1.5? How about using synonyms (shortened or “clipped” words) or words with similar meanings?
-
In the first row:
- if both prompts are the same, i.e. the prompt with “low poly” appended, then low poly is strongly emphasized compared to the 1st image on the 4th row previously.
- if prompts are swapped so that the style is in
CLIP_G, then evidently, theCLIP_Lencoder is unable to capture the essence of the prompt and is this is the wrong way to use the text prompts. - if the style “low poly” is appended to
CLIP_GandCLIP_Lis left blank - the output passable but less dynamic somehow...
-
In the second row:
- Per Clipdrop,
photographicis the “official” style (a rather odd word), - However, the clipped form
photo, produces worse results, - And
photographis oddly the worst.
- Per Clipdrop,
-
And similarly, in the final row:
- Per Clipdrop
cinematicis “official,” - It seems
cinemalooks worse, - But
filmis the worst.
- Per Clipdrop

It’s possible that the last 2 scenarios are specific to my prompt. Still, I’d best stick to the “official” styles for use with CLIP_L first, then append more style descriptors after that in a chaotic, un-directed, word-salad.
Experiments with Alternative Styles
WARNING: NSFW
What about other “typical” style prompts? I tried many... and here are the most interesting results!

Bonus! I am using the ComfyUI extension ImagesGrid to generate the image grid.
- For every LoadImage, use ImageCombine to add each image to the previous (it’s probably adding each image to an array / List).
- Since my images are added left-to-right, then top-to-bottom (Z), I use ImagesGridByColumn.
- To label the columns and rows, use the GridAnnotation node - the first text box sets column titles (delimited by
;), and the second text box sets row titles (again delimited by;).