The Stability AI documentation now has a pipeline supporting ControlNets with Stable Diffusion XL! Time to try it out with ComfyUI for Windows.
Get caught up:
Part 1: Stable Diffusion SDXL 1.0 with ComfyUI
Part 2: SDXL with Offset Example LoRA in ComfyUI for Windows
Part 3: CLIPSeg with SDXL in ComfyUI
Part 4: Two Text Prompts (Text Encoders) in SDXL 1.0
Part 5: Scale and Composite Latents with SDXL
Part 6: This post!
Updated 19 Aug 23: Since writing this post, Stability AI has released new Control-LoRAs, bringing “a more efficient and compact method to bring model control to a wider variety of consumer GPUs.” I’d suggest using those instead, rendering this content slightly obsolete in less than a week!
About ControlNets
The idea is that a ControlNet applies conditional “control” to influence SDXL’s text-to-image generation process, so that it follows the “structure” of the control. The control could be in the form of a reference image, an edge map, a depth map, or the a human body poses! Today, these ControlNets all exist for the original Stable Diffusion 1.5, but alas, I am focusing on SDXL 1.0...
As noted in the diffusers group controlnet-canny-sdxl-1.0 model card, “There are not many ControlNet checkpoints that are compatible with SDXL at the moment. So, we trained one using Canny edge maps as the conditioning images.”
The Canny edge detection algorithm was developed by John F Canny in 1986.
This ControlNet for Canny edges is just the start and I expect new models will get released over time. So, I wanted learn how to apply a ControlNet to the SDXL pipeline with ComfyUI.
FYI: there is a depth map ControlNet that was released a couple of weeks ago by Patrick Shanahan, SargeZT/controlnet-v1e-sdxl-depth, but I have not tried this.
Download ControlNet Canny
Since I am using the portable Windows version of ComfyUI, I’ll keep this Windows-only... (I am certain it will be too memory intensive and excrutiatingly slow on my lowly mac mini)
- From the official SDXL-controlnet: Canny page, navigate to Files and Versions and download
diffusion_pytorch_model.fp16.safetensorswhich is half the size (due to half the precision) but should perform similarly,- however, I first started experimenting using
diffusion_pytorch_model.safetensorsinstead, and this post is based on this version, and... - some people report success using the
.binfiles instead.
- Move / copy the file to the ComfyUI folder,
models\controlnet - To be on the safe side, best update ComfyUI. In the windows portable version, simply go to the
updatefolder and runupdate_comfyui.bat. - Start ComfyUI - I edited the command to enable previews,
.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build --preview-method auto
No-Code Workflow
I assume you have the usual nodes required for loading the SDXL base and refiner models, a workflow that is perhaps similar to my first SDXL post.
In that case, referencing the ComyUI ControlNet Example, only a small modification is required to generate a Canny edge map and apply that to the conditioning prompt, prior to the usual KSamplerAdvanced step:
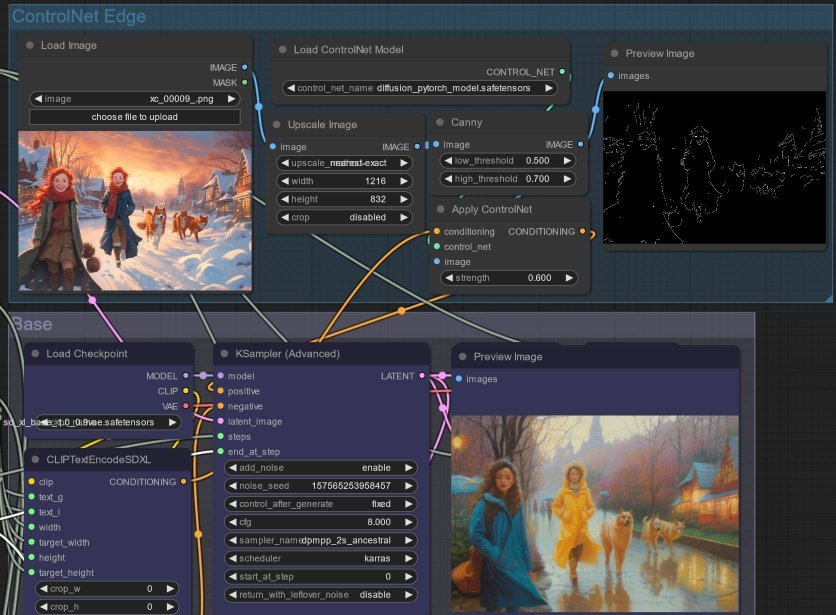
- Add a LoadImage node and load the source image.
- Optionally, wire the loaded image to ImageScale - and ensure image dimensions all line up.
- Then wire up the
imageoutput to a Canny node. For me, alow_thresholdof0.5and a high of0.7seemed to generate a sufficient edges to retain the impression desired without having the edges themselves show up in the output - it seems the higher the threshold, weaker edge output strength. - And, use a PreviewImage node to try and find the best balance - to save time, don’t proceed until you find a rather faint outline, similar to what I achieved.
- Wire the
imageto ControlNetApply as well as thecontrol_net- from the particular image in my experiment,0.6worked well. - Use the ControlNetLoader node to load the model downloaded (or use DiffControlNetLoader node if using the
.binfile), and wire the output to thecontrol_netinput in the ControlNetLoader node from the previous step. - Now, take the output
conditioningfrom the CLIPTextEncodeSDXL node, pass that into ControlNetApply, and use the resulting output as thepositiveinput of the KSamplerAdvanced node.
Experiments
I may be doing things wrongly, but here are some results...

To be honest, I’ve had pretty poor results with this ControlNet. While the generated output does conform to the general outline of the original image, the there is a noticeable lack of detail and the lacking in vibrancy.
The SDXL 1.0 and ControlNet models are both so huge I can barely run them on my GPU, so I have to break up the workflow into separate chunks, as described previously.
Additionally, the image generation takes is a shocking 15x times longer! This will no doubt improve in the (near) future, when smaller, more optimized models are released. That’s the power of the community when given open source tools and code!
Updated 19 Aug 23: As mentioned, I’d suggest using Stability AI’s new Control-LoRAs - you may wish to jump to my follow up post using these Control-LoRAs instead. These LoRAs are much smaller and faster to load, and are fine tuned so as not to impact image generation time!