In this post, I experiment with latent scaling and latent compositing with SDXL 1.0 using ComfyUI. That is to say, increasing / decreasing the size of the image, and combining multiple images into one à la green screen (chroma key) compositing.
Get caught up:
Part 1: Stable Diffusion SDXL 1.0 with ComfyUI
Part 2: SDXL with Offset Example LoRA in ComfyUI for Windows
Part 3: CLIPSeg with SDXL in ComfyUI
Part 4: Two Text Prompts (Text Encoders) in SDXL 1.0
Part 5: This post!
Image Scaling
Three posts prior, as bonus, I mentioned using an AI model to upscale images. Unlike scaling by interpolation (using algorithms like nearest-neighbour, bilinear, bicubic, etc.), an AI model instead will add “missing” pixels based on what it has learnt from other images. This method can make faces look better, but also result in an image that diverges far from the true image (ground-truth)!
Upscaling AI models that can be used are listed in this Upscale Wiki and I have tried:
- Real-ESRGAN
- 4xUltraSharp - this is not an “official” repo, but I do not think the creator Kim2091 has one. Use at your own risk.
Aside: It seems that ComfyUI does not support Stability AI’s Stable Diffusion x4 upscaler... yet?
Latent Scaling
Instead of scaling the output image, what happens if we scale the latent space instead? The simplest (inaccurate) ELI5 is, because the latent space is a mathematical representation of the text prompt mapped to learnt images - prior to being decoded into an image - therefore, upscaling the latent and then decoding will also result in a larger image... right?
Ah yes, but! Since the latent is merely a representation, the scaled latent is, more likely than not, going to look totally different once decoded. However, this is fine for me since I’m generating an AI image from scratch, as opposed to intending to recover loss of fidelity e.g. from a real photograph.
I learnt about this method by looking at the ComfyUI Noisy Latent Composition Example and adapted it for SDXL.
So let’s experiment:
- first, latent downscaling and latent compositing i.e. making latents (and resulting images) smaller and “merging” these latents into a larger latent space to create a “mash up” of multiple latents - this allows creation of complex, multi-subject images that the CLIP text encoder simply cannot understand in a single pass.
- then, we look at latent upscaling and do a very unscientific comparison with an AI-based upscaling model.
Experimenting with Latent Downscaling and Compositing
First, add a parameter to the ComfyUI startup to preview the intermediate images generated during the sampling function.
On Windows, assuming that you are using the ComfyUI portable installation method:
.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build --preview-method autoOn macOS, assuming you’ve using my manual method of installing:
source v/bin/activate
python3 main.py --preview-method autoNow, we can create the flow, which, in short, is something like this:
- As usual start with the CheckpointLoaderSimple node, and load
sd_xl_base_1.0.safetensors, - Create the background by wiring up the prompt CLIPTextEncodeSDXL and a 1216 x 832 EmptyLatentImage to KSamplerAdvanced, enabling
add_noiseandreturn_with_leftover_noisewith20steps but stopping at step7, - Repeat this two more times to create two figures, but this time, pass each output latent through a LatentUpscale node and downscale to 512 x 608 as in my example, or any other size.
- Next use LatentComposite twice, each time setting the position of the two scaled image relative to the background, add feather as you see fit, then:
- wire up
samples_toto the latent from the first KSamplerAdvanced for the background andsamples_fromto the second KSamplerAdvanced, - and wire up the next
samples_toto the output of the first LatentComposite node andsamples_fromto the third KSamplerAdvanced.
- wire up
- Create a new CLIPTextEncodeSDXL that describes the desired image in its entirety, and then wire that up to...
- a final KSamplerAdvanced stage, this time disabling
add_noiseandreturn_with_leftover_noiseand starting at step7out of20, and using the output of the second LatentComposite node aslatent_image, and finally, - As usual, pass the output through VAEDecode and finally SaveImage nodes.
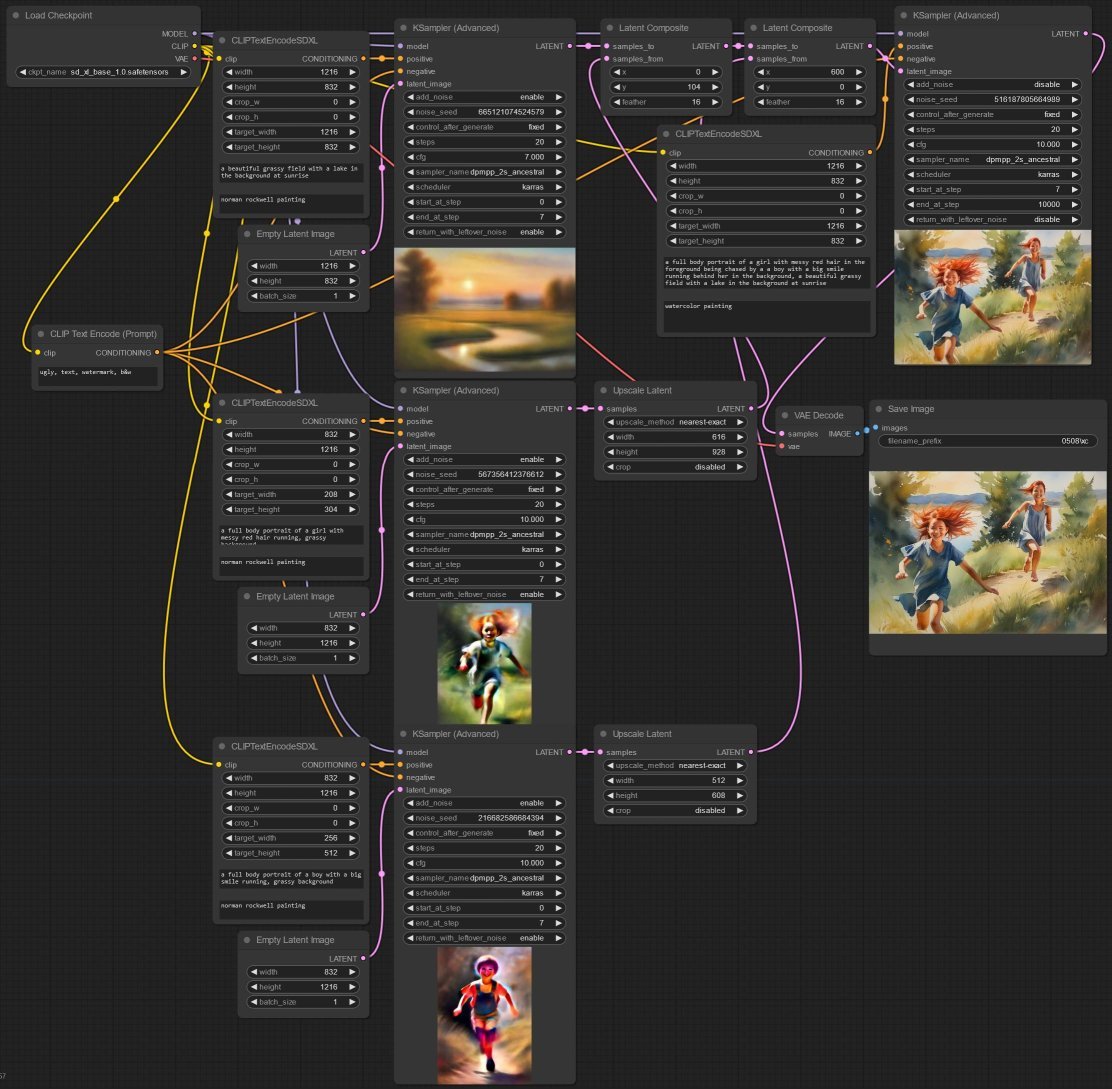
There are no hard and fast rules when it comes to the KSamplerAdvanced parameters. So, keep an eye on the preview, and adjust the parameters to an intermediate output that is roughly to your liking (especially steps, start_at_step and end_at_step) . Alas, I cannot explain this well... suffice to say use your eyes!
I stopped at around step 7 because that gave me a clear enough idea of the pose of the figures. I then fixed the seed and you can see figures the final image retain the same approximate pose.
Notes:
- I kept the
cfgvalue low during the first stage of latent generation via KSamplerAdvanced but set a higher value for the final stage, in order to better preserve the earlier outputs. - Do not create EmptyLatentImages with arbitrary sizes - stick to the image sizes SDXL is trained on (see the list at the end of my previous post)
- Do use LatentUpscale to scale latents to any arbitrary image size desired prior to compositing.
- Apart from the steps, do experiment with the scale, feather and X/Y location of each composite - this gave me really interesting, coherent layouts with multiple characters as seen below (I also adjusted the prompt in the second set of images):

Aside: I tried the MultiLatentComposite Davemane42's Custom Node v1.1 to graphically position the composited latents, but that caused an issue that locked up the UI.
Experimenting with Latent Upscaling
I believe that highres-fix often cited with Stable Diffusion 1.5 is latent upscaling. I think this also works with SDXL but the results are not great, though I haven’t really done sufficient testing.
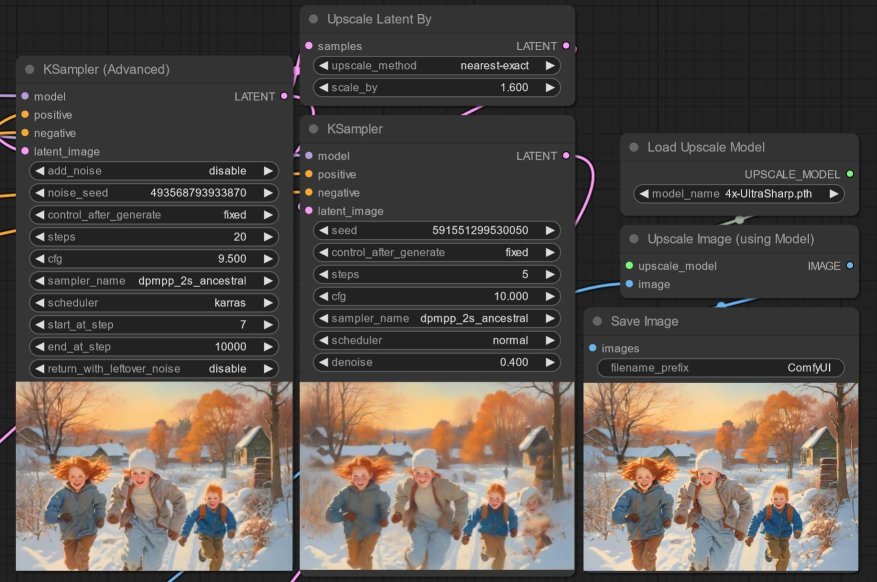
- The first image is the original AI generated image...
- The second image is generated by a UpscaleLatentBy node by 1.2 times and then a basic KSampler node with a
denoisefactor - the noise introduced has resulted in a fourth ghostly figure! - The third image is result of using AI upscaling using the
4x-UltraShparp.pthmodel - which is still not sharp once zoomed in!
Notes:
- Denoise factor should be around
0.4-0.5to more-or-less preserve the image structure. - Sampler and Scheduler selection really makes a difference and to me, the basic ones are better than ancestral ones.
- Upscale latent in small increments repeatedly, rather than attempt a large upscale like 2x.