Yesterday I mentioned in passing that my Nvidia RTX 2060 with 12GB could not run both SDXL 1.0 Base and Refiner models in a single ComfyUI workflow. Today, I show you my workaround and also experiment with adding the SDXL 1.0 Official Offset Example LoRA to the workflow.
Get caught up:
Part 1: Stable Diffusion SDXL 1.0 with ComfyUI
Part 2: This post!
About LoRAs
Low-Rank Adaptation (LoRA) is a method of fine tuning the SDXL model with additional training, and is implemented via a a small “patch” to the model, without having to re-build the model from scratch.
The SDXL 1.0 release includes an Official Offset Example LoRA . The metadata describes this LoRA as:
SDXL 1.0 Official Offset Example LoRA
This is an example LoRA for SDXL 1.0 (Base) that adds Offset Noise to the model, trained by KaliYuga for StabilityAI.
When applied, it will extend the image's contrast (range of brightness to darkness), which is particularly popular for producing very dark or nighttime images. At low percentages, it improves contrast and perceived image quality; at higher percentages it can be a powerful tool to produce perfect inky black.
This small file (50 megabytes) demonstrates the power of LoRA on SDXL and produces a clear visual upgrade to the base model without needing to replace the 6.5 gigabyte full model. The LoRA was heavily trained with the keywordcontrasts, which can be used alter the high-contrast effect of offset noise.
Recommended strength: 50% (0.5). The keywordcontrastsmay alter the effect.
FYI this metadata is found at the start of the .safetensors file itself.
Install ComfyUI for Windows
So easy:
- Download the ComfyUI Standalone Portable Windows Build (For NVIDIA or CPU only) and extract.
- Download the models like previously on macOS, but this time, also get the example LoRA:
- Download
sd_xl_base_1.0.safetensorsfrom huggingface.co stabilityai/stable-diffusion-xl-base-1.0 and save it in the folderComfyUI\models\checkpoints(yes: there is a newer version; no: I do not know what the differences are), - Download
sd_xl_offset_example-lora_1.0.safetensorsfrom the same folder and save it inComfyUI\models\loras, - Download
sd_xl_refiner_1.0.safetensorsfrom huggingface.co stabilityai/stable-diffusion-xl-refiner-1.0 and save it toComfyUI\models\checkpoints.
- Download
- And, run
run_nvidia_gpu.batorrun_cpu.bat
Create No-Code Workflow
This time I won’t describe it too much. Suffice to say,
- Create the flow like previously, then:
- After the CheckpointLoaderSimple node which loads the base model, add a LoraLoader node - the LoRA downloaded should be selected already so just set the strength e.g.
0.5to0.8, then wire up:- model and clip outputs from CheckpointLoaderSimple to LoraLoader
- model
and clipoutputs from LoraLoader to KSamplerAdvanced and CLIPTextEncode (for the negative prompt) respectively. Correction: I had better results not using the LoRA clip, instead all clip inputs should be from the original CheckpointLoaderSimple
Updated 17 Aug 23: As posted recently, increasing the Windows virtual memory paging file size resolved this for me so I no longer need this workaround:
To workaround my memory limitation:
- After the first VAEDecode node, I have to add a SaveLatent node.
- Instead of wiring up the base model latent output to the refiner, I have to add a LoadLatent node and then wire up the output latent to the KSamplerAdvanced refiner node.
Now, to run the Base model (in green):
- Right-click the base model’s CheckpointLoaderSimple and LoraLoader nodes one by one, and select Mode > Always to enable them.
- Right-click the refiner’s CheckpointLoaderSimple and LoadLatent nodes one by one, and select Mode > Never to disable them.
- Now I can hit Queue Prompt to run the only the first mode. ComfyUI will highlight the nodes of the refiner model with a red border, to indicate they could not be run.
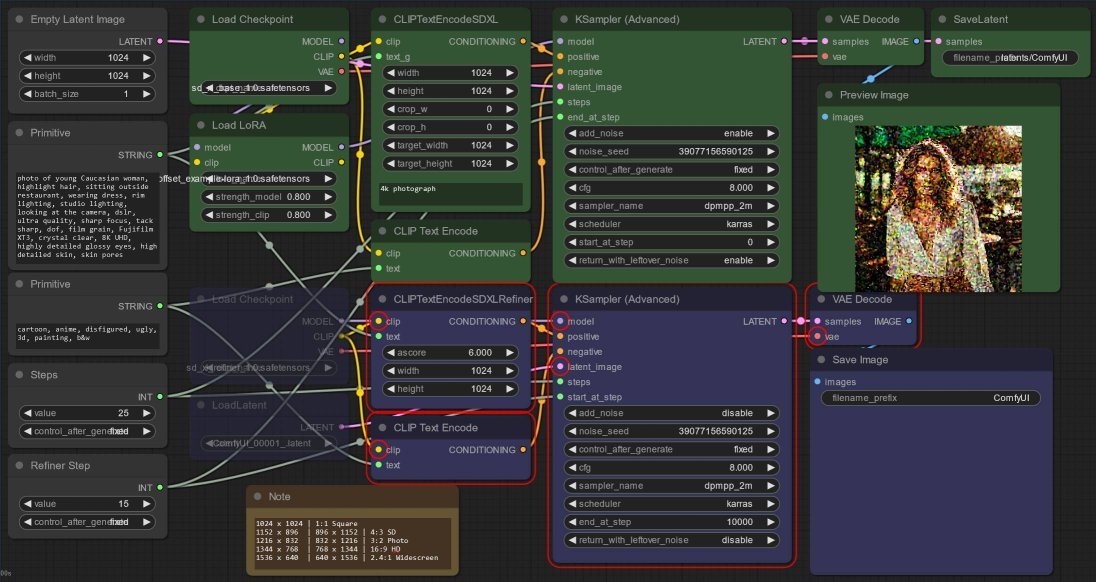
And to run the Refiner model (in blue):
- I copy the
.latentfile from theComfyUI\output\latentsfolder to theinputsfolder. - Then refresh the browser (I lie, I just rename every new latent to the same filename e.g.
ComfyUI_00001_.latentto avoid this) - Do the opposite and disable the nodes for the base model and enable the refiner model nodes.
One final tip: Once your settings are all correct, simply open a new browser tab and use one browser for the first Base model, and the other browser tab for the Refiner. A small batch script works for me to copy the output latent to the input folder, e.g. copy /y %1 ..\..\input\1.latent by dragging-and-dropping the latent. Still manual, just a bit less manual intervention.
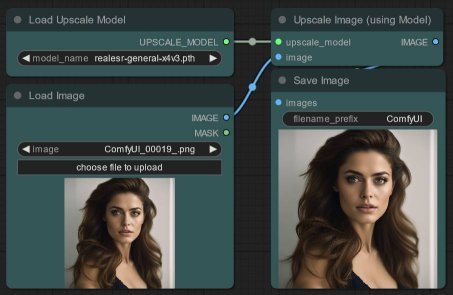
Bonus: I actually have a third section in my workflow (in cyan), which is shown below - that section runs Real-ESRGAN to upscale images. You can do the same thing - just download realesr-general-x4v3.pth from the Real-ESRGAN v0.3.0 Release Notes page and place the file in the folder ComfyUI\models\upscale_models first. Then add the UpscaleModelLoader and LoadImage nodes and wire up the outputs to ImageUpscaleWithModel:
Experiment with LoRAs
Comparing the output without (left) and with (right) this LoRA, you can certainly see - even though it is an example - that it certainly fulfills its promise to “improve contrast and perceived image quality.” I do so prefer the LoRA version!

FYI the prompt is based on guidance at Stable Diffusion Art on ‘How to generate realistic people in Stable Diffusion’.
Many more LoRAs are available at Civitai, and I’m sure support for SDXL 1.0 will only grow.
Corrected 1 Aug 23: Updated the screenshots since I think the LoraLoader clip output should not be used.
Updated 17 Aug 23: As posted recently, increasing the Windows virtual memory paging file size resolved my memory error RuntimeError: [enforce fail at ..\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate ###### bytes.