Stability AI just released an new SD-XL Inpainting 0.1 model. Here is how to use it with ComfyUI.
Installing SDXL-Inpainting
- Per the ComfyUI Blog, the latest update adds “Support for SDXL inpaint models”. With the Windows portable version, updating involves running the batch file
update_comfyui.batin theupdatefolder. - Go to the stable-diffusion-xl-1.0-inpainting-0.1/unet folder,
- And download
diffusion_pytorch_model.fp16.safetensorsordiffusion_pytorch_model.safetensors- I use the former and rename it todiffusers_sdxl_inpaint_0.1.safetensors, because it is 5.14 GB compared to the latter, which is 10.3 GB! - Place it in the ComfyUI
models\unetfolder. - Re-start ComfyUI.
SDXL Base in-painting
Here is a simplified version of the workflow I previously described using CLIPSeg with the SDXL model for in-painting, using the SDXL base model for in-painting:
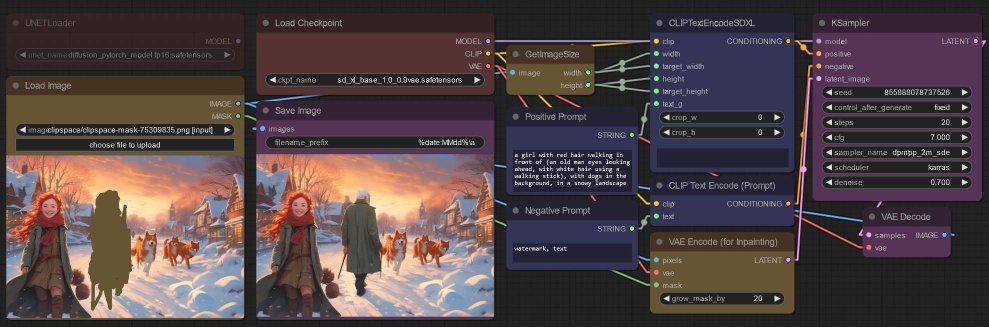
- I used a LoadImage node mask the image (right-click and Open In Mask Editor). The image is then...
- wired to a GetImageSize node, from the stability-ComfyUI-nodes, just for convenience so I do not have to determine the source image dimensions manually,
- and wired to a VAEEncodeForInpaint node, used in place of an EmptyLatentImage node - I increased the
grow_mask_byso as to avoid visible “edges” around the masked area. - Then the
latentoutput from the VAEEncodeForInpaint node is wired up to the KSampler node. - The rest of the workflow is the typical SDXL workflow... I merely placed the final generated image beside the source image just for easy comparison.
SDXL-Inpainting
Here is the workflow, based on the example in the aforementioned ComfyUI blog.
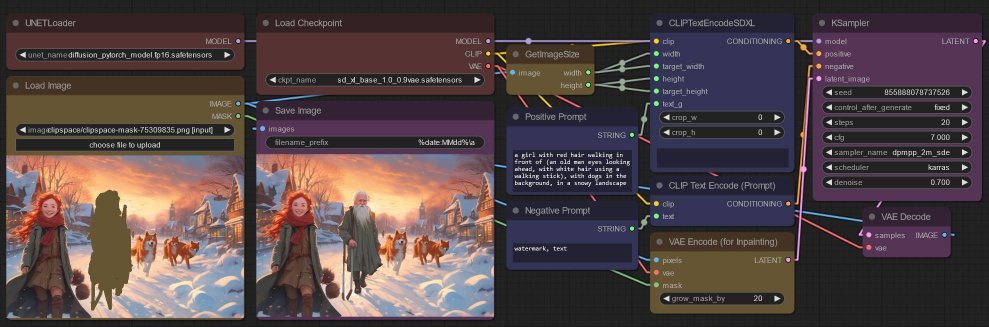
- The UNetLoader node is use to load the
diffusion_pytorch_model.fp16.safetensorsnode, - And the
modeloutput is wired up to the KSampler node instead of using themodeloutput from the previous CheckpointLoaderSimple node.
In this case, this model certainly produced a better image. Of course I cherry picked the best!
Summary
I only used this one image so I draw no conclusions. Is the output always better with this model?The model is very large, and SDXL Base model can also be used for in-painting.
Just a few words about what I noticed:
- I did not use any words to describe the style of the image, and I left the second
clip_lprompt blank. - Both models did well to appreciate the art style and generate something that fit properly.
- I originally just described the masked area, e.g.
an old man..., but I found that describing the whole image worked better. Hence my prompt also includes words abouta girl with red hair... dogs in the background, etc. I have no idea which is better. - But the models both seem to prefer colors present in the rest of the image... I can’t get the old man in a jacket of a different color.