More and more AI generated images are shared as short video clips. So, here a quick test of Stable Video Diffusion - which was released back in November last year. Don’t know why I didn’t post this when I posted about AnimateDiff and the Hotshot Motion model around the same time.
Installing
The latest version of ComfyUI supports Stable Video Diffusion natively.
Just download either the 14-frame stable-video-diffusion-img2vid model,svd.safetensors, or the 25-frame XT model, svd_xt.safetensors. Place either or both files in ComfyUI\models\checkpoints\, but I only use the former, since I have insufficient VRAM for the latter...
Workflow
Nothing unique here: the workflow is per the second ComfyUI video example:
- I am using the Juggernaut XL model to generate the initial frame.
- Followed by the Stable Video Diffusion mode - remember that the video model is trained for 576 x 1024.
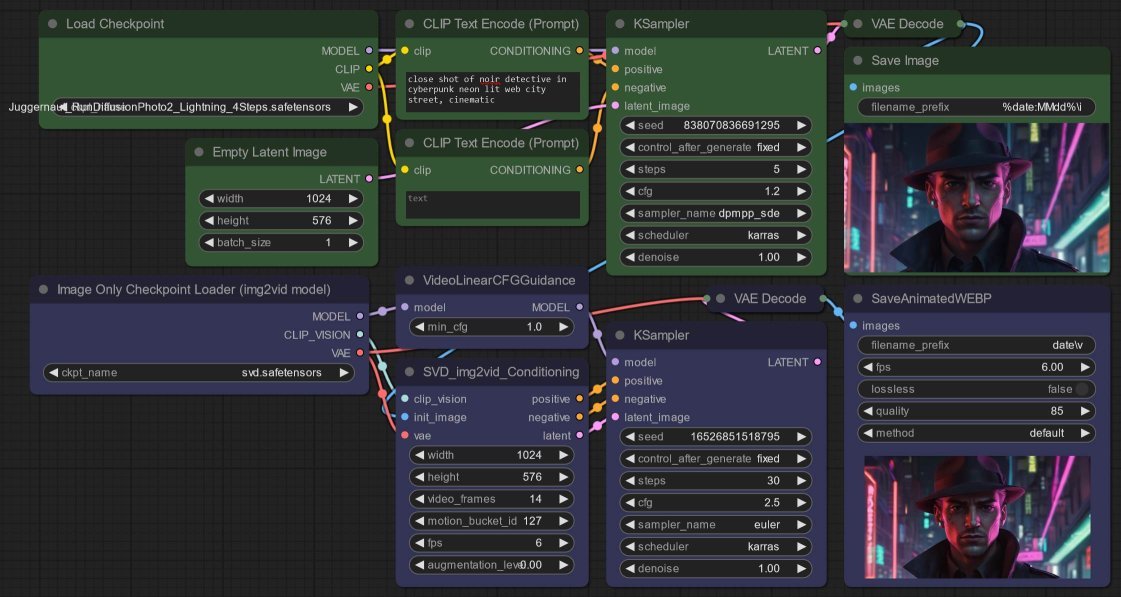
Mainly, video model is more focus on camera motion, with a little bit of character motion like walking or arms swinging. Don’t expect it to generate complicated character motions.
On my GTX 2060, once the models are loaded, 5 + 10 steps completes in ~1.5 minutes, while 5 + 30 steps takes ~2.5 minutes.