In the span of a couple of weeks, we got Crazy fast image generation with LCM LoRA for SDXL, which led me to ask if I could get Faster Stable Diffusion on M-series macs?. A few hours ago, Stability.ai gave us their response in the form of SDXL-Turbo... and now we go even faster!
From the model card:
SDXL-Turbo is a fast generative text-to-image model that can synthesize photorealistic images from a text prompt in a single network evaluation.
Installing
Before proceeding, do update ComfyUI - git pull or update_comfyui.bat if you are on the Portable Windows version.
Download the SDXL-Turbo model from HuggingFace, I am using the fp16 version which is a whopping 6.94 GB!
BTW the update will break ComfyUI Core ML Suite, which I used in my last post - the error is cannot import name 'ModelSamplingDiscreteLCM' from 'comfy_extras.nodes_model_advanced'.
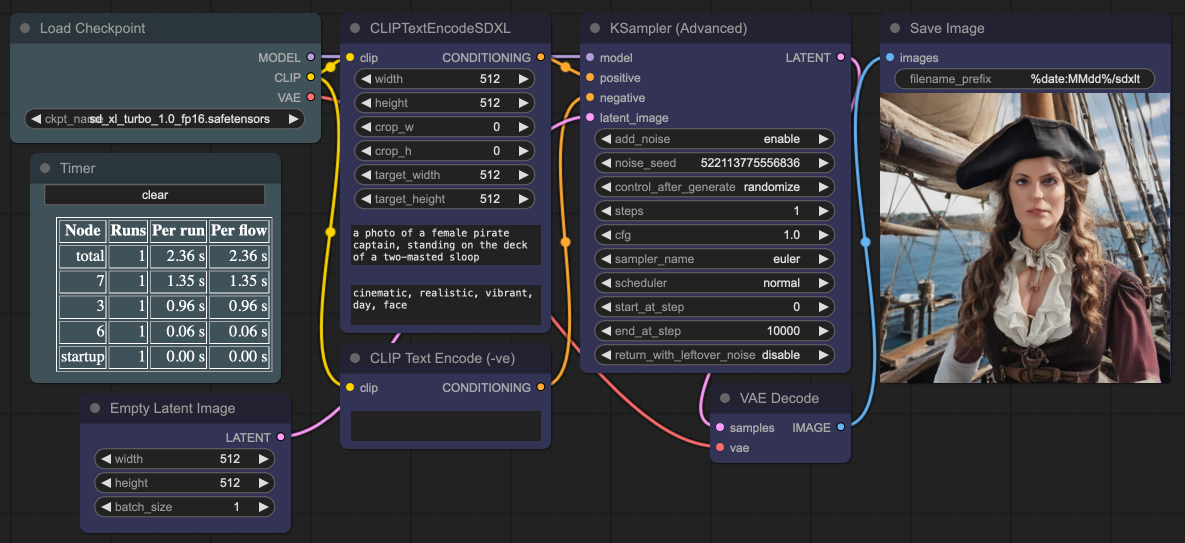
Workflow
Here is what I use:
- use just 1
step! 2 is ok, but the more steps, the worse the results - the model card says to set guidance_scale = 0, but do not - use
cfgof 1±0.2 instead, any anything else is bad - negative prompts are not used
- generated images are fixed at 512x512
- generating people is pretty much a fail - “Faces and people in general may not be generated properly”
- not all samplers work, Euler will do
When I first posted about AI-generated images with Stable Diffusion on an M1 mac on 16 September 2022, I made a comment that I was getting “render time from 1-2 minutes (MPS) to 10-15 minutes!” With an exclamation mark even!
That was on an M1 Pro with more GPU cores, but today I am using a M2 Mac Mini base model. I am unable to make a direct comparison, but now after the initial loads and with the same cached prompt, each run is just ~3 seconds - I am at a loss for words.